1.
Numérotation des images scannées :

|
Page impaire. |
Page
paire. |
 |
- de 001 à ... : les pages d'informations (image de couverture, titre, auteur, etc...)
- de 010 à ... : les pages de texte,
en leur ajoutant la lettre “a” pour les impaires et “b” pour les paires.
2.
Traitement des images : |
Grâce
à ScanTailor,
je peux :
Premier onglet : corriger l’orientation,
Deuxième onglet : scinder en deux les doubles pages,
Troisième onglet : redresser les pages pour obtenir des lignes
parfaitement horizontales,
Quatrième onglet : définir les zones de contenu,
Cinquième onglet : définir les marges autour de ce contenu,
Sixième onglet : générer des pages homogènes.


3.
L' OCR ou la reconnaissance de caractère |
A
partir de ce dossier, je passe l'ensemble des images dans Abby
FineReader.
a
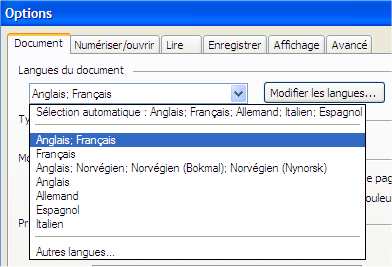
: Mes options
Je choisis les langues
en fonctions du livre. |
 |
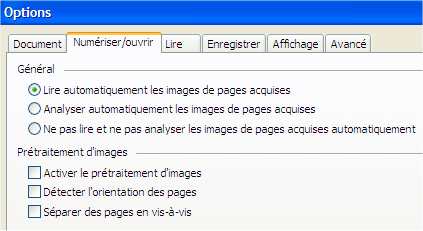 |
Le prétraitement
des images a déjà été effectué
avec Scan Tailor. |
| Texte sous l’image de page permet de conserver l’image de scan originale avec la couche de texte invisible issu de l’OCR. | 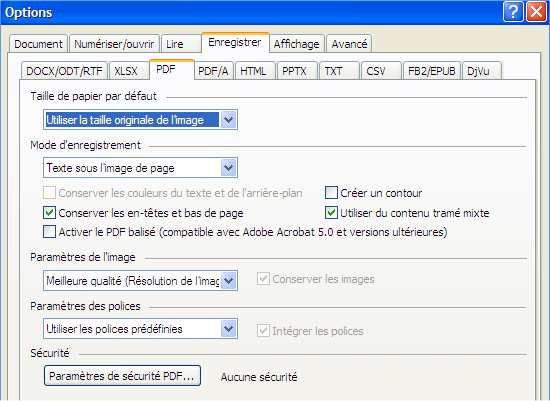 |
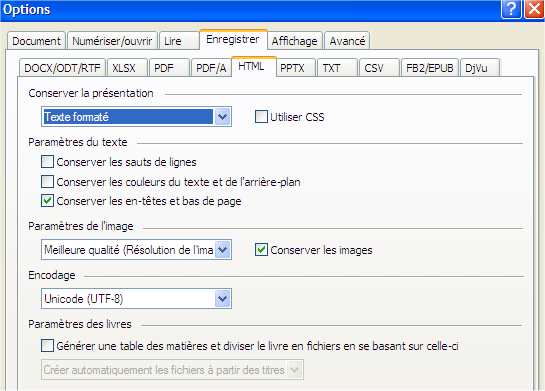 |
Pour l'instant, J'ai préféré garder le texte formaté avec le numéro de page. |
b
: Utilisation
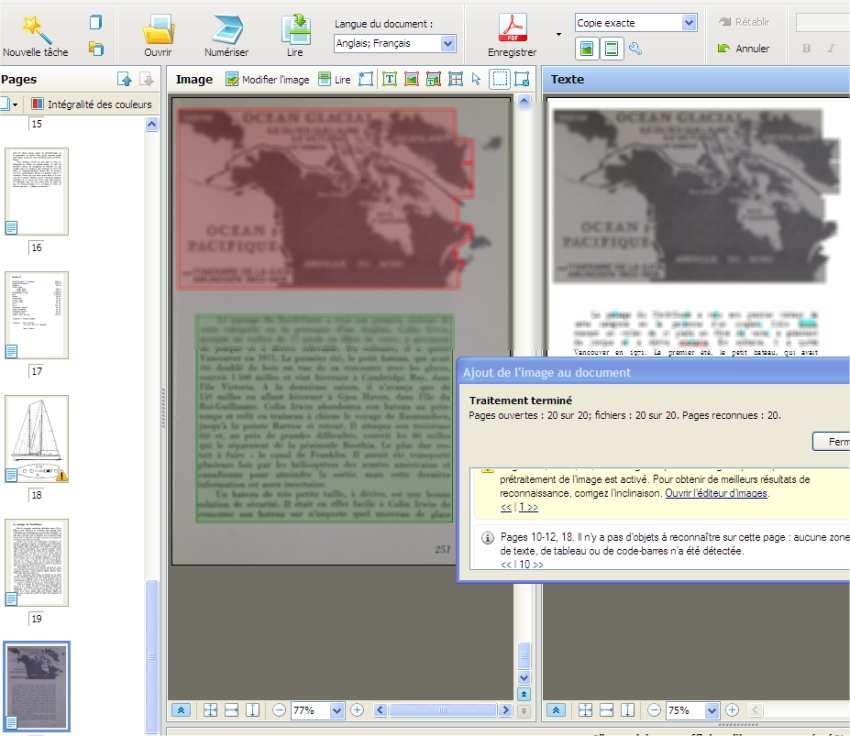
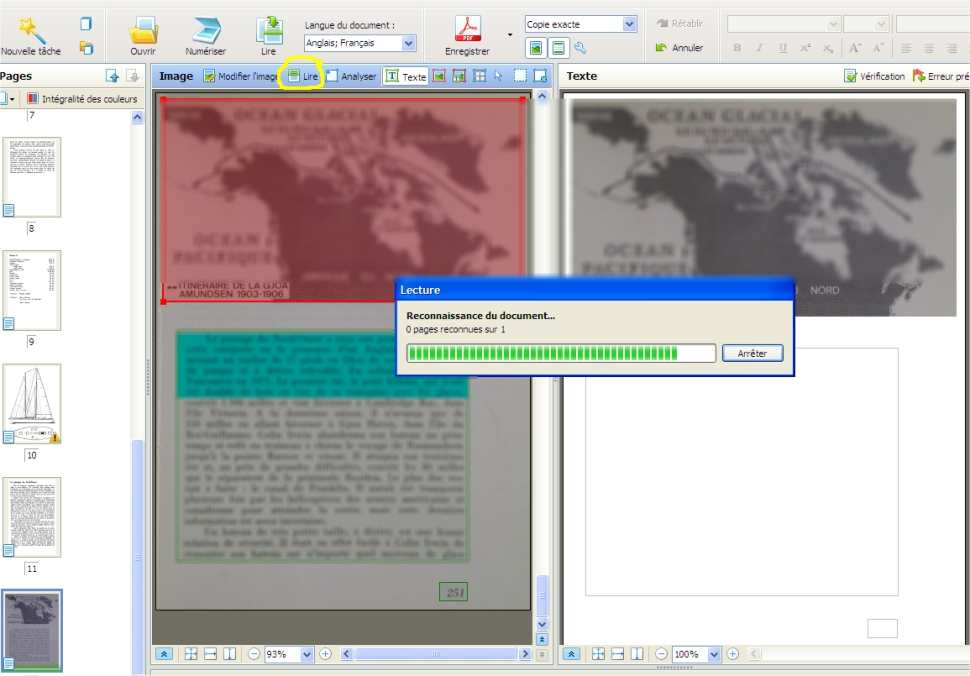
Si je modifie une zone, je relis la page en cliquant sur le bouton « Lire » juste au-dessus de l’image (entouré en jaune) pour enregistrer les modifications
- un au format PDF qui facilitera les recherches éventuelles lors des corrections ou des relectures.
- un au format HTML que j'ouvre ensuite dans un traitement de texte pour procéder aux corrections, Word en ce qui me concerne .
les
livres d'un même auteur sont regroupés dans un dossier à
son nom (ex : Auteur).
3ème
partie : Traitement du texte |
|